In my previous post I went through a thought process to identify a fitting class of data structures to contain unique set of strings. We have, through that process of elimination identified Burst Trie (BT) as leading candidate. In this post we are going to explore in detail how that works.
Acknowledgements
Subject covered in this writing is mainly based on a paper first published (in 2007) , titled ‘A Fast, Efficient Data Structure for String Keys”, by Steen Heinz, Justin Zobel and Hugh E. Williams at School of Computer Science and Information Technology, RMIT University. Credit goes to them. In this paper they go through the process of studying existing structures as well – for example, Hash Table. However, it is not explicitly identified that Hash Tables do not provide prefix matching in the same efficient way as Trie does or any tree based data structure for that matter.
The graphs in this writing were created using an online free tool at draw.io – Created by the same folks who created the awesome jGraph library. Thanks to them for making this available for free. There is a commercial version, please support.
Anatomy of Burst Trie
Moving on we are going to identify the organs of this data structure as explained in this paper.
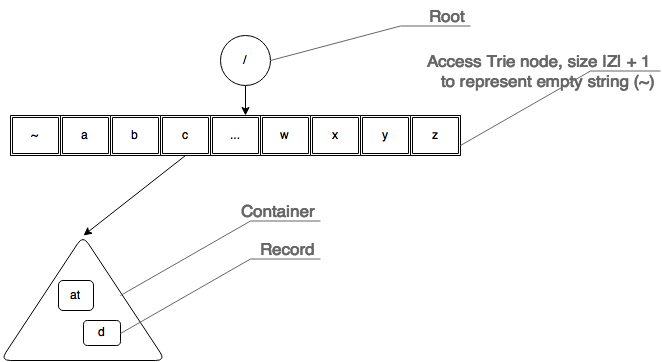
- Records – a record is more than a string. It is conceived as an object that ‘contains’ string or one that ‘points to’ a location where string is located. Further, a record may contains details such as stats on the string itself.
- Containers – a container contains collections of records. It goes through the stage of ‘burst’ thus creating new containers. So if a container is found at level ‘k’, then all records in that container has ‘k’ number of characters and share the same prefix of ‘k’ length. A container also has a header for storing stats (such as how frequently it has been accessed and so on) and heuristics as when and how it should be burst. As said earlier, a container is a collection. What data structure to use to represent the containers is examined later. Typically it can be a Hash Table, Binary Search Tree (BST – in such cases records can be kept in sorted order) – we will examine it later.
- Access Trie – is just a Trie. Each node of the trie is an array of size |Z| – where Z = { set of target language alphabet }. Each index in this array either points to a trie node or a container. Array may not be a suitable choice when |Z| is larger – for example Tamil alphabet, as opposed to English.
Building the BT
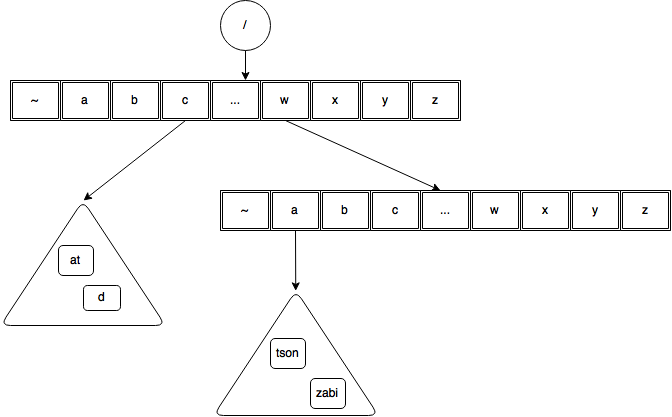
Burst Trie can grow in two ways. When new record is added to a container or when a container gets burst. Let’s take an example.
Note
It is important to note that a Burst Tree starts its life as single container and not as a Trie node. Only when this first single container is burst will a access trie node get added.
Bursting : How
Bursting, as said earlier is one of the ways BT grows. Let’s take a look at a BT before it is burst
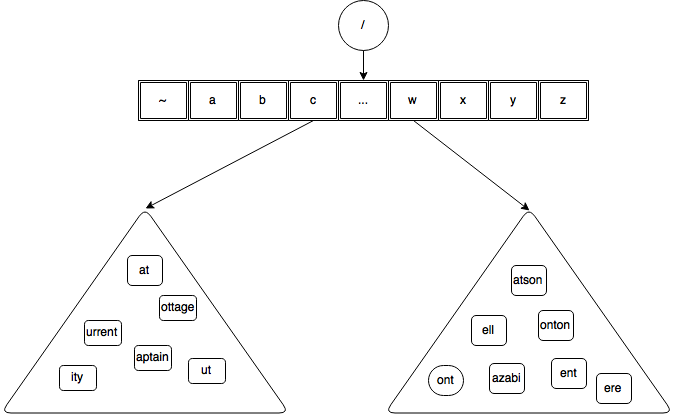
Now, let’s assume, there is a heuristic such as follows associated with the containers concerning bursting routine : that is, burst a container when the count of distinct characters with which suffixes start is more than 3. Whether or not this heuristic is sound is not subject of discussion at this point. That is the ‘When’ part of burst routine. We are discussing only about ‘how’ part.
From the above diagram it is clear that container on the left hand side has suffixes starting with ‘a’ , ‘o’ , ‘i’ and ‘u’ – which is more than 3 therefore it is a candidate for bursting. The container on the right hand has only three distinct characters with which its suffixes start – so it is not ripe yet to be burst.
Let’s see how the tree would first look like after bursting.
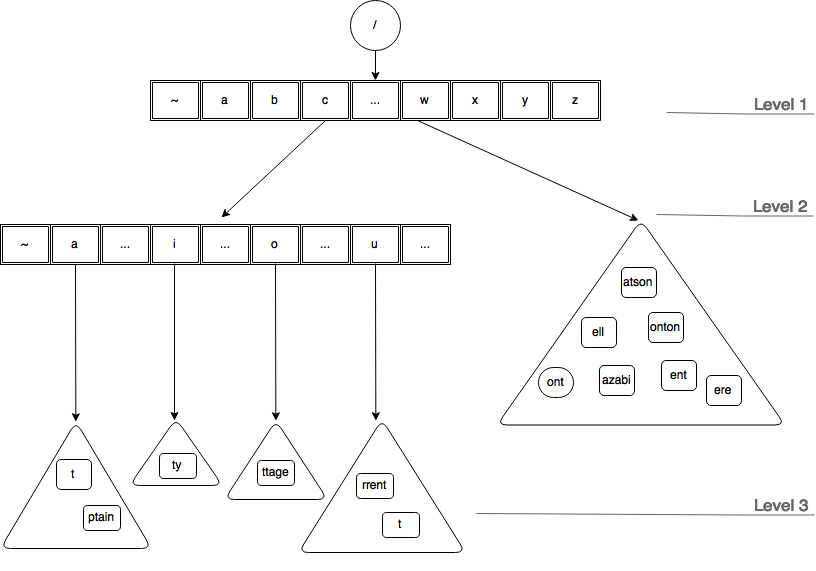
As can be noted above a new level (level 2) has been introduced, first character from each suffixes (from the original container) was promoted to a (access) trie node and rest of the suffix is bucketed into containers according to their fist character (that was promoted). For example, ‘aptain’ has become ‘ptain’ and its first character ‘a’ was promoted to the newly created trie node.
Bursting : When
When to burst a container is what going to determine how well this data structure works for a given business case. Heuristics facilitate a tuning mechanism. For example, in the above example, heuristic was if the number of distinct characters were more than 3 then the container got burst into smaller ones. In the academic paper mentioned above, few heuristics were analyzed – I am just going to mention it here for your reference. But before I do that, let’s see what makes a better behaving Burst Tree. If there are heavier bursting then BT is more like just a Trie, becoming not so efficient with the space. It is stated in that paper, empirically, optimal number of bursts achieves faster BT. That is less searches in the container but not entirely without any containers (or containers with just one record – meaning got burst to the max). I quote the followings from that paper so as to give you some guidelines in choosing a heuristic that works –
“A successful bursting strategy should, then, ensure that common strings are found quickly via the access trie, without excessive searching within containers“
“A bursting strategy should also ensure that containers that are rarely accessed are not burst, since containers should be more space efficient than trie nodes.“
“…in other words, a goal of bursting is to transform containers that have high average search costs, without bursting unnecessarily.“
So, that’s your rule of thumb(s). Because if there is extensive bursting, to a point every container has single node, then the BT behaves more like a Trie, on the other hand if there is going to be extensive search within a container then that’s may not behave like a trie at all.
Burst Heuristics
let’s assume the data structure used for managing records in container to be Binary Search Tree (BST).
Heuristic : Ratio
Each container to maintain two counters. One for direct hit (h) – that is search has found the value at the root, the other one was to track how many times the container has been searched (q).
So, ration r=q/h, that is, if the ration was calculated to be 2:3, for any given 100 queries against BT, 40 of them ended up as container search while 60 of them were direct hit. Now, threshold can be set so that if ‘h’ were to decrease below percentage, say 80%, then container should be burst.
Ratio : Disadvantage
- Two variables are required to track the counters thus increasing memory footprint of a container
- Calculation cost at the time of access
Heuristic : Limit
Idea here is to maintain single counter to track the number of records in the container and if that exceeds a threshold then bursting the container. Thinking behind here is that reducing the size of high traffic container would in turn reduce the average access cost.
Limit : Disadvantage
- Even a low accessed container can potentially burst
- On the other end of spectrum, if number of records in a container is less than the limit, then it will not get bust even it it is heavily accessed – in such cases BT will perform poorly.
Heuristic : Trend
The idea is this – a single variable with an initial capital value ‘c’. Every time there is a search then a fixed penalty ‘p’ is deducted against ‘c’. Every time there is a direct hit, capital increase is made by a bonus amount ‘b’. If the capital is exhausted then the container is burst. The thinking behind this idea is that if there are more search than direct hits then the capital would be exhausted flagging this container as a suitable candidate for bursting. On the other hand if the values were predominantly found at the root (direct hit) then capital will not be exhausted thus space would be kept optimally (by not getting burst).
The values for c,p and b were found (authors report of optimal values of 5000,32 and 4 respectively) empirically as reported in the academic paper. You may need to do you own experiments to see what suits your need.
Containers : Data Structures
Design goal is to find a data structure (DS) that is not only time efficient but also space efficient for small number of records. Hash table is not such a DS. So, the candidates as (move-to-front) linked lists, Binary Search Tree and Splay Trees are considered. Splaying (rotations that move the last accessed node closer to root) is empirically found to be expensive. BST is a good candidate. BST, on average provides O(log n) access and is space efficient for small number of records as well.
Conclusion
As we have discussed so far, Burst Trie is a good candidate for suggestive searches – or generally for maintaining unique set of string in memory and providing a time and space optimized access to these strings. It also provides prefix matching. So, there you go.
